Why is a smart clothes dryer sending and receiving the equivalent of 68 YouTube videos (1GB of traffic) every day?
Are you wondering why, like us, a smart clothes dryer is sending and receiving over 1GB of daily traffic to an EC2 instance on Amazon Web Services (AWS) every day?
Over the weekend of 10-11 April 2021, there was a flurry of comments to a post on r/smarthome, a Reddit subreddit dedicated to smart home devices. A Redditor had posted about finding out that their LG dryer (a DLE3500W model) was using a hefty amount of their home internet bandwidth, even though it’s just a smart clothes dryer.
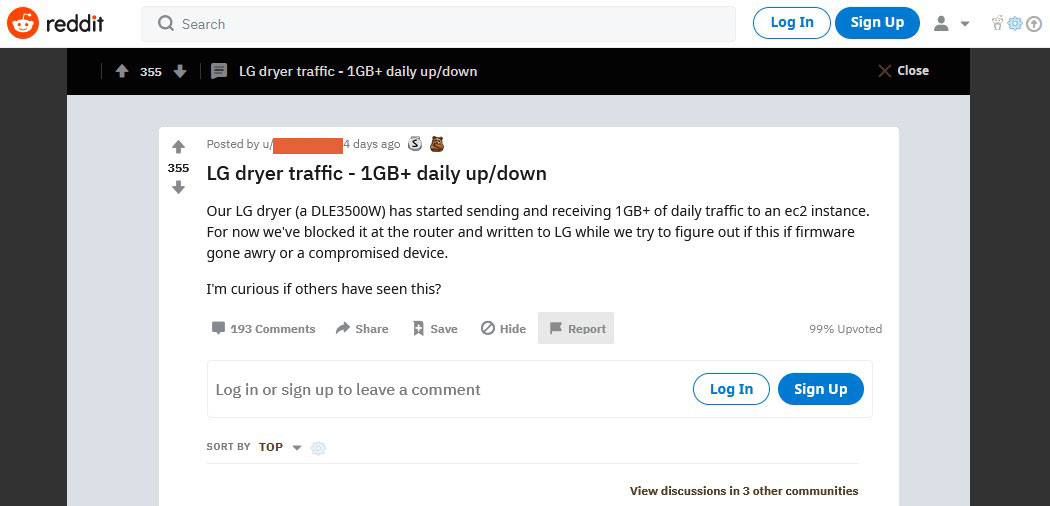
Redditors replying to the original post were quick to suggest something malicious was going on with this IoT product. After all, there’s a story about security issues with IoT devices every week.
(Case in point on security: while writing this blog, news broke about a series of vulnerabilities involving domain name parsing in DNS implementations for the TCP/IP stack (dubbed Name:Wreck) that puts IoT devices at risk.)
But has this smart device been hijacked for use in a botnet or mining cryptocurrency? Or is something else at play?
And what can you do to help embedded software development teams prevent products from behaving in this way and causing issues for users and your business?
Users don’t want a connected product that needlessly sucks up bandwidth
Before we get deeper into the details of the dryer, let’s dip our toes into User-Centred Design for a second and take a moment to think about the end-user here.
With any consumer smart device that uses the internet at some point, that data, that traffic, needs to go across various networks, especially if the product connects with a cloud-based platform.
If the product is home-based, it’s likely on a home network on a residential internet connection. Users won’t want their smart device swallowing up bandwidth across their internal network and their internet connection. The reasons for this are many, but might include:
- Metered connections (they could have a monthly data cap).
- Slow connection speed (they could be using an FTTC connection or 4G or slower).
- Their home router doesn’t have much bandwidth available on its channels.
- Their home router doesn’t have customisable user settings to set bandwidth priorities, or it does, but the user doesn’t know how to use those settings on their router.
- The user has bigger priorities for what they want to use their home network and connection for, like streaming, multiplayer videogames, homeworking, video chats and so on.
How big of an issue could any of these be? Considering our 1GB dryer example, the most important thing to remember is that hardly anyone has high speed internet connections in their home. Squeezing 1GB of data you weren’t expecting to be sending or receiving can eat into what’s available for the platforms and devices you do want to be using that connection.
After all:
In 2019, globally, only 5% of people had access to gigabit internet.
Source: Viavi Solutions
And there hasn’t been much progress on this figure in the past two years. Do you know anyone with gigabit internet at home? No one on our team does.
Even Starlink (Elon Musk’s satellite internet venture) will only serve up to 150Mbps internet to users who don’t live in urban areas.
Now that you understand why having a dryer consuming vast amounts of bandwidth is a problem let’s go back to the clothes dryer.
The suspects
Without examining the dryer in question and sniffing its data packets or reverse-engineering the contents of those packets (all data sent to and from AWS must be encrypted, it’s a policy for using its infrastructure), we can’t find out for sure what’s going on. But there are three likely suspects, and two are more likely than the first.
Our suspects:
- Least likely: A dryer with a system that’s been compromised and is running malicious code, perhaps as part of a botnet or cryptocurrency mining ring.
- More likely: Inefficient sensor logging data being sent more often than it needs to be to an EC2 instance on AWS.
- Most likely: A file being sent, rejected, and sent again, like a firmware update that is stuck in a loop as it keeps being sent then rejected and is therefore unable to install correctly.
Again, we can’t say for sure which is happening here, but we can look at what each means for end-users and your product and business.
Least likely: The dryer’s security is compromised
The most popular option put forward in the discussion we saw was that malicious code was at play. But why do we think it’s the least likely scenario?
The first clue is where the data is going. Replies to the Redditor’s original post with the data-hungry dryer, explain that the data is going to LG’s API endpoint on AWS. A compromised device would not be doing just that. A compromised IoT product would have some data going to a genuinely suspicious endpoint.
The second clue is that the size of the data overall. It doesn’t reflect the size usually involved with an IoT product that has become a zombie device as part of a botnet involved in Distributed Denial of Service (DDoS) attacks.
Conversely, it’s unlikely to be anything to do with crypto mining. When a hijacked IoT device is used in crypto mining, it doesn’t normally involve large amounts of data for an IoT device.
Verdict: it’s unlikely it’s a compromised dryer.
Of course, we can’t rule out a malicious problem, as we haven’t examined the product involved. It not being malicious is just a best guess.
However, just because this is unlikely to be a security issue doesn’t mean you shouldn’t be thinking about the overall security of an IoT product you’re developing.
In the first half of 2020, there was a 50% increase in cyber-attacks on IoT devices.
Source: SonicWall
Meanwhile, prosecutors on cybercrime cases are starting to look further up the supply chain for who to hold responsible when serious incidents happen.
So how can you work to ensure your product is developed and programmed with security in mind?
Three ways you can work to secure IoT devices during development
There are several primary considerations during software development that can help you ensure that you’re minimising the risk of an IoT device being compromised:
- Consider security from the start of a project. Even if it’s saying, “We might need to think about security at some point.”
- Aim to minimise the attack surface:
- Limit superficial or redundant connectivity methods.
- Only have the necessary features and remove ones that fall out of use or are superseded in future version updates (bonus: this makes maintaining code easier).
- As much as possible, have only one way to perform anything the device needs to do.
- Gate behaviour correctly being authentication that includes a transparent permissions system.
- Realise there’s a trade-off between going in-house or third-party for software:
- In-house code has less exposure to malicious actors (in theory, but there are several ways it can become exposed).
- In-house code may be less secure as it doesn’t have as many eyes on it.
- Third-party options that are open-source, like Linux, have more people guiding its development and updates.
- Third-party open-source software is more likely to be targeted by hackers because it’s more widely available.
There’s more you can do, and you can read about it in our article on balancing connectivity and security in IoT and IIoT.
But what about the more likely scenarios at play here with the dryer?
More likely: Bloated and excessive sensor logging
Again, we don’t know if this is happening with the clothes dryer, but sensor logs could be behind the 1GB data puzzle. Sensors are a vital part of embedded systems in IoT, enabling physical events to be monitored by software and acted upon by the user or the smart device itself.
For this sensor information to be something that users can interact with, at some point, it needs to be interpreted in a user interface on the device itself or in an app on maybe a smartphone. In the case of a fitness band, that interaction might look something like this:
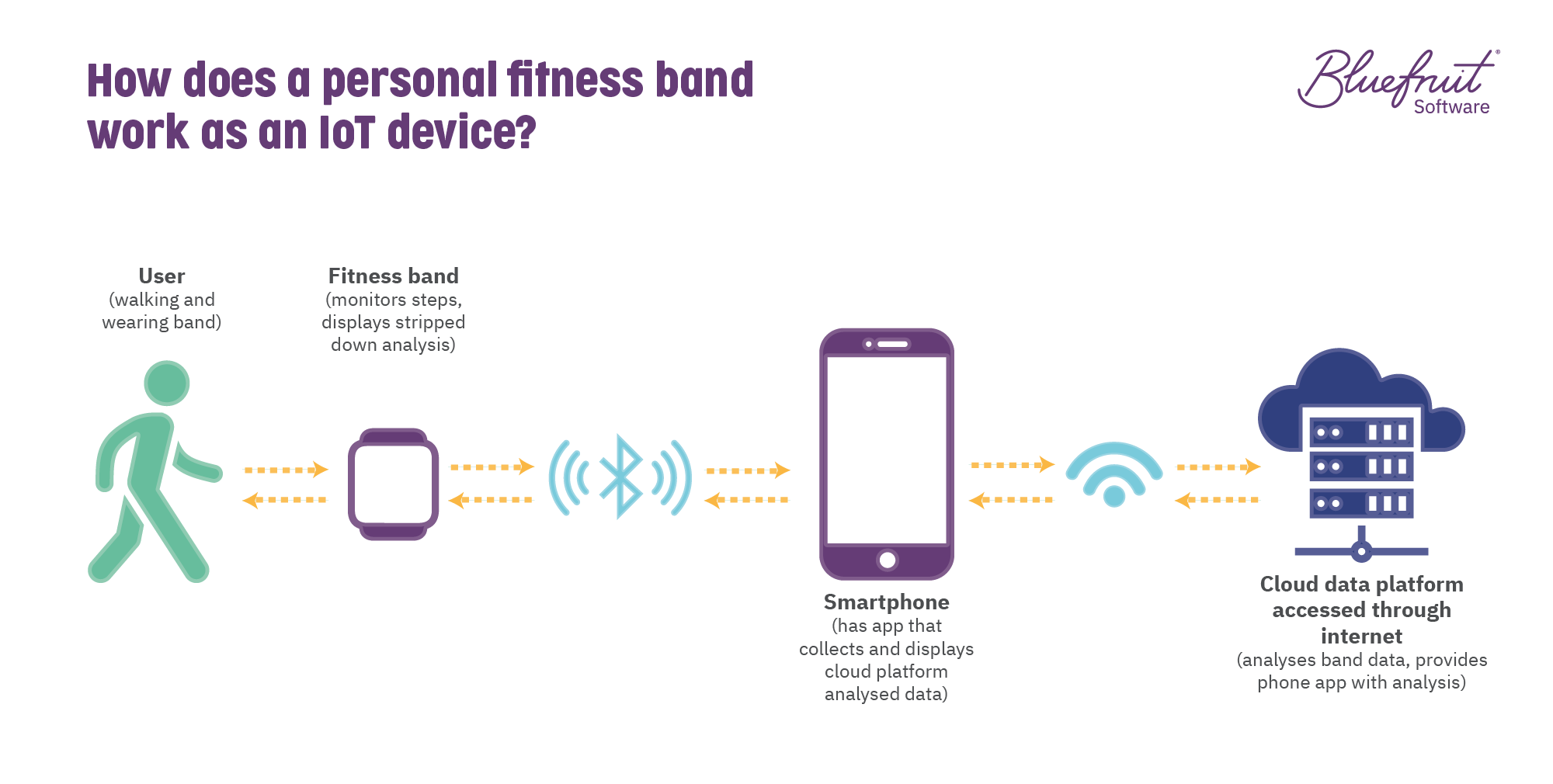
A series of replies to the original r/smarthomes post also suggested sensor logs could cause the mystery 1GB of data.
The theory was baulked at in the replies, but it’s not as improbable as you might think.
Once you start going from machine code to something more human-readable (like XML or JSON) and not a binary format, data can begin to balloon in terms of the memory it takes up. Then if you’re sending and receiving that data many, many times in a short period, it can add up.
In the embedded software world, this tension between binary and text is already well known, especially in green software engineering and ultra-lower power environments.
Using text rather than binary:
- Increases the computational load of a system.
- Increases power usage by the device.
- Increases the power needed to transmit data.
- Increases the file size of logs.
Why have logs at all?
For a business, logs can be handy for gathering usage data that can further product development and new R&D (depending on local privacy agreements laws).
For end-users, it’s the display of this information in meaningful ways that adds to some smart devices’ functionality.
But at some point, your business will pay for data bloat in its IoT products
If you’re using IaaS (Infrastructure as a Service) products like AWS, it pays to keep data costs down depending on how many active product units send and receive data. Even self-hosted solutions have overheads for sending and receiving all this data if it’s not processed locally by consumer units.
Your business will pay for bloat at some point.
Verdict: there’s a reasonable chance that sensor logs are behind that 1GB.
Still, we’re not sure that sensor logging could be behind this excessive bandwidth use. But it’s a problem you can avoid.
Three questions to ask your team to ensure efficient sensor logging and use
Here are a few questions to ask your software and product teams:
- How much sensor data does our product need to be sending and receiving to get the required functionality?
- Sensors should mainly be inactive when the product isn’t in use—don’t encourage unnecessary sensor logging.
- Batching sensor readings together can cut overhead.
- Don’t have sensors reporting more often than necessary—in the case of the clothes dryer, little will change in the space of a second. Minute to minute should be sufficient.
- Is our product using a binary format for sending and receiving data or a human-readable language?
- Once you go beyond most binary formats to human-readable languages like XML or JSON, you’ll find that they need more computational power than binary and massively bulk up sensor data packets.
- Field names being overly wordy (verbose) adds significant overhead (if forced to use XML or JSON, or similar).
- Software teams can improve the use of a binary format through writing habitable code, but it will only help so much in making sense of it.
- Can we use a binary format for sending and receiving sensor data?
- Sensor logs may need conversion at some point to something a person can read, but it doesn’t have to be happening for sending and receiving that data in the first place (if you have an accompanying cloud platform app for users, the conversion can be happening in the cloud).
- If your product needs to send sensor data tens of times a second, that data needs to be in binary.
- Ensure the team uses an efficient binary format, as some are bulkier than others.
There’s more your team can do but considering the above is a good start.
Still, we don’t know for sure if sensor logs are behind the mystery with the LG dryer.
Now, on to our final suspect.
Most likely: A failing firmware update process
The evidence that this is a firmware-over-the-air (FOTA) process update going awry comes from the discounting of a security issue, plus the repetition of what’s happening, and the overall size of the data involved. It’s a theory suggested in the replies to the original post on r/smarthome, and it’s a good theory.
It’s not uncommon for a firmware update process to fail and then loop back to trying again. That problem is common for over-the-air (OTA) updates without sufficient measures to handle it.
Verdict: a high possibility that it’s a failing firmware update process.
In this case, the user is lucky that their dryer appears to still function as a dryer. Why lucky?
Sometimes FOTA and OTA can go very badly. Here are just a few examples of OTA gone bad:
- Google accidentally “bricked” some Google Home products with a firmware update, leading to many devices needing replacement.
- About 500 LockState smart locks were suddenly rendered unusable by a FOTA update and needed owners to perform a very hands-on fix.
- Samsung managed to brick thousands of its customer’s Blu-ray players with an XML configuration file download that broke the players’ firmware. Affected systems needed replacing, at cost to Samsung.
IoT has seen a rise in updates bricking devices and devices needing replacement at a cost to businesses. There have also been devices otherwise rendered unusable by updates until a fix is applied. Bouncing back from this kind of reputational damage can be tricky.
But a great benefit of smart devices is the ability for software teams to push updates to them. Being able to force updates is also crucial when fixing critical security holes in software.
Equally, this means there’s a real need to perform effective embedded software testing to check that updates don’t break devices or can be done in the first place by users.
Five ways your software and product teams can minimise the risk in OTA updates
There are ways software teams can make updates more accessible and less likely to fail. As well as having a robust testing process, measures can include:
- Developing as frictionless an update process as possible. Reducing the need for direct intervention by end-users can help lessen the risk of user error causing problems with updates and ensure that critical patches happen. Ease of use for updating can also be essential for smart consumer devices because many people don’t have the digital skills to get hands-on with their device. At a bare minimum, performing a factory reset should not be complicated.
- Providing a meaningful method for end-users to find out what’s wrong with their device. Equally, for users who are more comfortable with technology, you should make the ability to find out why something is wrong as simple as possible and fixing it easy as well, or at the least an error message that a support team can act on.
- Having a limit on failed download and install attempts and having a cool-off period between the series of attempts when they fail. For example, maybe the device will try ten times to update and if each attempt in this series fails, have a pause for several hours before trying again.
- If using AWS for OTA, be expressive in communicating fails to AWS. Why? AWS can take that data and make decisions based on it. It could be that it shows AWS it needs to abort the process because the update can’t happen right now due to some reason. And software developers will also see that feedback and know that something is wrong and start working on a fix.
- Embracing Test-Driven Development (TDD). Why? It’s a beneficial technical practice for software teams to engage in because (aside from several other benefits) during development, software engineers can respond more effectively to defects uncovered through testing or after deployment.
Again, there are more measures that software and product teams can take to ensure firmware updates and other patches are less likely to fail. It also depends on cost and customer support availability and whether some options are more practical than others.
Smart devices are only brilliant when you make intelligent design and software choices
We still don’t know what’s happened with the data-hungry smart dryer, but its behaviour should be considered a bug and certainly not a feature.
With the increasing risk of legal action, risk to reputation, and the ongoing business costs from poorly configured software for smart devices, it makes sense to reduce these business risks during the software creation process.
When you want to speak with a software and testing team that makes a point of high-quality embedded software development on every client project: reach out to Bluefruit Software.
(Note: This blog’s title is from the idea that 68 YouTube videos are the same as around 1GB, based on each video being around four minutes each in length and are MP4 files.)
Did you know that we have a monthly newsletter?
If you’d like insights into software development, Lean-Agile practices, advances in technology and more to your inbox once a month—sign up today!
Find out more




