Machine learning and embedded systems: exploring the relationship
We now live in an age where companies must amass vast amounts of data to stay competitive. That’s just the way it is.
This data arms race is important for organisations to improve business operations. That’s why Big Data, machine learning, and embedded systems are joining forces for greater performance. The real challenge is using machine learning for real-time insights on embedded systems with inherent limitations.
For example, hardware constraints are obstacles to embedded machine learning. That’s why companies that implement on-device machine learning have a competitive advantage. This includes improved operations, lower costs, increased security, and reduced human error. And who doesn’t want that?
In this guide, we’ll look at how companies can use machine learning to optimise their embedded systems. We’ll cover the basics of big data, embedded systems, and machine learning. We’ll even discuss combining these fields to achieve a massive competitive advantage. Soon you’ll know how to overcome the challenges of on-device machine learning.
Table of contents
The growth of Big Data
Big Data describes the enormous amount of information that today’s enterprises accumulate daily. These datasets are often too large or complex for traditional data processing. That’s why many companies use machine learning to analyse big data and generate relevant insights.
The rise of big data comes as companies continue to digitise their operations. This includes more devices connected to the Internet. These devices—smartphones, tablets, smartwatches, cameras, all fitted with sensors, and more—collect data at a staggering rate each year. It’s projected that the volume of data created worldwide could reach 149 zettabytes by 2024! Storing vast amounts of data has been a challenge with traditional relational databases. That’s why many organisations use cheaper alternatives like data lakes or data warehouses.
While big data is on the rise, it’s still challenging for many companies to collect large amounts of data. With embedded systems and machine learning, organisations can still achieve results with smaller datasets. In the upcoming sections, we’ll take a look at why embedded systems are fuelling data growth. We’ll also cover how machine learning can tap into this treasure-trove of information.
What are embedded systems?
An embedded system is hardware and software designed to perform a dedicated function. The software is “embedded” directly into the hardware during development. Some embedded systems are independent, while others work as part of a more extensive system or network. Embedded systems vary in complexity, from simple microprocessors to multicore processors. More complicated systems include graphical user interfaces and other connected peripherals.
A microcontroller (MCU) is an integrated circuit chip that includes a CPU, memory, and input/output. A microcontroller has all the peripherals for running software. In contrast, microprocessors only have a CPU and thus require additional components like external memory to function. Companies deploy embedded systems on microcontrollers. That’s because they’re cost-effective, self-contained, and designed to run a single application.
Embedded systems designs
An embedded system is software running on a microcontroller. Developers build the software for a particular device and function. That means the systems have specific memory and processing requirements. While the term “firmware” is often used interchangeably with embedded software, it refers specifically to the low-level software tightly integrated with the hardware’s design.
Many embedded developers build embedded software from scratch. Others use an operating system as a starting point. If developers don’t use an operating system, it’s called a bare metal solution. Bare metal is great for low-end microcontrollers but isn’t ideal for advanced features like connectivity.
A real-time operating system (RTOS) enables data processing without buffer delays. Many embedded developers use RTOS to streamline the development of real-time embedded software. Real-time embedded systems are classified as hard or soft real-time. Hard real-time systems fail when they miss deadlines. Soft real-time can miss deadlines with degraded performance.
When using microprocessors, most developers choose an operating system like Embedded Linux. The memory requirements for Linux are much higher than RTOS. But using an operating system eliminates the boilerplate code. That means developers can create a proof-of-concept much faster.
Embedded systems range in performance. The general classifications are small, medium, and sophisticated or complex systems. Small scale systems often use 32-bit microcontrollers. That means they’re small enough to be powered by a battery. Medium-scale embedded systems are capable of more complicated tasks. Cutting-edge applications use sophisticated embedded systems. These offer the highest level of hardware and software performance.
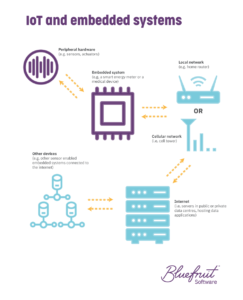 IoT and IIoT explained
IoT and IIoT explained
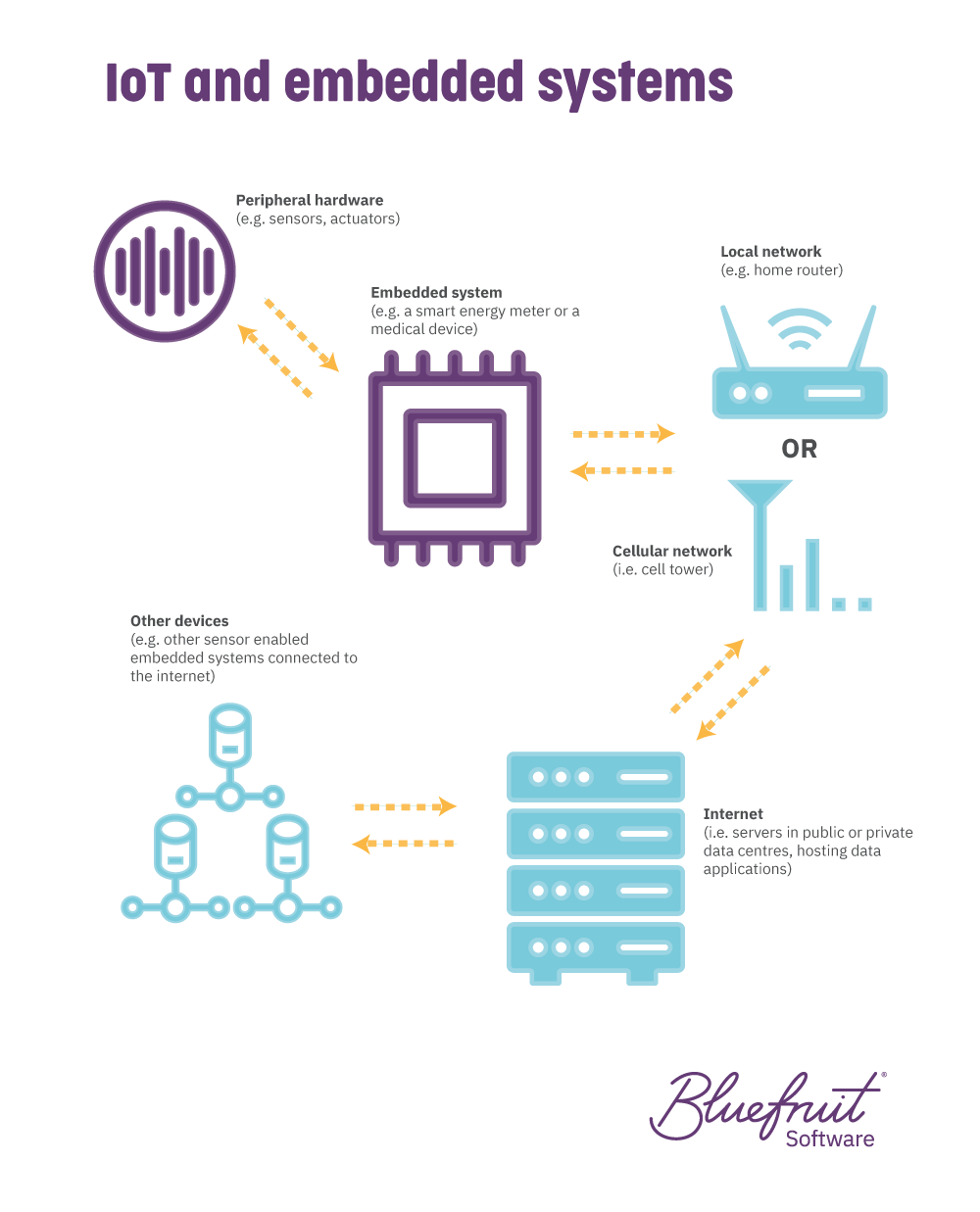
The Internet of Things (IoT) is a growing area for embedded systems. As hardware becomes cheaper, more embedded devices are connected to the internet than ever before. IoT is the network of interconnected embedded devices that exchange data with each other. IoT refers to consumer devices.
Besides connected devices meant for consumers, IoT projects are transforming industrial processes. Industrial Internet of Things (IIoT) refers to sensors that collect data for real-time analytics. IIoT improves the efficiency, reliability, and safety of business processes. Like consumer IoT products, these are connected to a network. IoT and IIoT embedded systems are useful for a wide range of use cases and sectors. This includes robotics, medical, automotive, networking, appliances, industrial, and more.
How machine learning works
Machine learning (ML) is a category of artificial intelligence (AI) that learns from data. ML then applies these insights without humans. Using statistics, machine learning can identify patterns within large datasets or Big Data. The software scope is no longer limited because ML algorithms can develop new processes on-the-fly.
However, the quality of ML insights varies. This depends on the data’s structure, the algorithm’s technique, and more. For example, supervised algorithms use pre-labelled datasets during training. Unsupervised algorithms use unclassified data. Input data quality is an essential factor for achieving accurate and high-quality ML outputs.
What is deep learning?
Deep learning is a subset of machine learning. It uses an artificial neural network to determine accuracy. Neural networks replicate human reasoning using multiple layers to analyse data. The more hidden layers, the “deeper” and more complex the deep learning becomes.
Neural networks consist of anywhere from a few dozen to a few million neurons or units. There are input and output units at each end of the network, with numerous layers of hidden units in between. These interconnected units have weights representing their relative importance.
The initial weights of the deep neural network are random. Still, backpropagation enables the algorithm to compare actual results against desired results. The algorithm then adjusts unit weightings to improve accuracy. Data scientists train deep learning algorithms using backpropagation. After the model is deployed, backpropagation allows the algorithm to continue learning.
Image recognition, natural language processing, and translation, use neural networks. As data scientists refine machine learning algorithms, businesses will apply them to both small and large datasets.
How are ML models built and deployed?
Most developers use machine learning frameworks to streamline the implementation of ML models. Machine learning is data-centric, so developers need tools to simplify the maths and statistics involved. This decreases the time-to-market and cost for implementing embedded ML.
Some of the most popular ML frameworks include TensorFlow, Pytorch, and Caffe. These frameworks provide everything developers need to build, train, and deploy machine learning models through a simple programming interface.
The first step is for developers to choose a framework and algorithm. The embedded system and data requirements will determine this. Many frameworks include tools for creating data formats and performing data transformations. Developers should carefully consider the features essential for the ML models they’re building.
A model can then be trained using labelled datasets. This happens before deploying to the cloud or embedded systems. Developers will need a large dataset to split between training and testing sets. Missing or mislabelled data can negatively impact effectiveness.
Once ML models are trained, it is deployed to either run on-device or in the cloud as an inference system. An inference system makes predictions based on a trained ML algorithm. This works by feeding data into the algorithm to calculate outputs.
Benefits of combining ML and embedded systems
 By combining ML with embedded systems, companies can gather data, analyse it, and make predictions. This process can improve their hardware and business-critical systems’ performance. With deep learning, companies can achieve a level of embedded systems intelligence that wasn’t possible before.
By combining ML with embedded systems, companies can gather data, analyse it, and make predictions. This process can improve their hardware and business-critical systems’ performance. With deep learning, companies can achieve a level of embedded systems intelligence that wasn’t possible before.
For example, image and speech recognition has been a challenge for computers. In the past, software couldn’t analyse enough data to learn. The sheer amount of variations possible couldn’t be accounted for. Cheaper and more powerful hardware enables embedded systems to replicate human-like tasks.
ML is often used to learn more about sensor or device behaviour. This is useful for preventative maintenance, anomaly detection, and improved efficiency. Companies can identify patterns for device decay that engineers may not be aware of. ML can reduce the cost of embedded systems while overcoming their constraints.
Cloud versus on-device ML processing
While most ML, AI, and data processing workloads run in the cloud, there’s a trend for on-device-AI (also known as edge AI). On-device-AI means deploying models on edge devices to infer directly at the data source. Since data predictions occur locally, companies don’t need an outside network that could introduce risks. On-device-AI ensures that sensitive data remains unexposed to the public internet.
Cloud-based AI/ML requires embedded devices to send data to the cloud for inference. The cloud gives companies virtually unlimited computational power, but introduces latency. There’s always a delay when transmitting data to and from embedded devices. Embedded systems are often deployed in locations where connectivity is severely restricted, so running ML inference offsite isn’t practical. There can also be security and privacy concerns with transmitting data to an outside network. That said, this approach is useful for algorithms that require massive amounts of data.
Most embedded systems developers train their ML algorithms in the cloud or using high-performance computers. The trained model that does the inference is then implemented on the devices themselves. This ensures embedded systems aren’t bogged down while still making predictions close to the data source.
Why ML for embedded systems is challenging
Machine learning may be beneficial for embedded systems performance, but it is still challenging to implement. Here are some of the obstacles from hardware and framework limitations to data variances and latency.
Hardware constraints
Embedded devices often have limited memory, processing power, energy capacity, and more. Since embedded systems are designed for specific uses, there’s limited resources leftover for ML. That’s why most implementations only handle the inference phase locally. The training of the ML models is done in the cloud or offline beforehand. Some embedded implementations also leverage additional hardware accelerators like GPUs or FPGAs.
Framework limitations
Many of the most common ML frameworks aren’t ideal for embedded devices. They create models that are too large and require rich runtime environments. Alternatives like TensorFlow Lite can offer on-device inference optimised for embedded systems. But light frameworks may not support advanced features. Some models can also be interpreted using a lightweight inference engine. This is ideal for embedded systems environments.
Data variances
Another challenge is the varying conditions in which embedded systems collect data. While larger datasets can cover more variances, embedded systems may not have the capacity. Embedded systems using cloud-based ML discard a lot of the data they collect. The problem is that companies are losing out on potential insights from a granular-level analysis.
Latency
Limited local resources are a challenge for real-time ML. Companies often overcome limited processing capacities using cloud-based machine learning. The problem is additional latency may not be acceptable for some applications. That means cloud-based inference can limit the potential use-cases for ML. This is especially true for IIoT environments with uncertain conditions and privacy concerns. (And if the connection goes and the system is offline, it could have consequences for any critical functions that rely on the system being online.)
Security and privacy
Besides latency, using cloud-based machine learning with embedded systems introduces risks. Connecting devices to an outside network could open an attack vector. There’s risk of data interception, spoofing, or hacking. Algorithms with “invisible” layers could also create challenges from an auditing and compliance perspective.
(Take a look at our article on the challenges of AI and embedded systems for more information.)
Overcoming embedded systems limitations for ML
While machine learning is challenging to implement in embedded systems environments, the obstacles aren’t insurmountable. Here are some ways to overcome embedded system limitations for ML. These tips include selecting the right algorithm, curating data, and dividing ML processing.
Algorithm selection
First, companies need to leverage machine learning algorithms optimised for embedded systems deployments. That means software that efficiently utilises device processing power to analyse data locally. ML also shouldn’t compromise the embedded system’s primary tasks. For example, embedded developers can use a library like CMSIS-NN. This simplifies implementing a neural network on microcontrollers. Many frameworks can also use GPU-accelerated libraries to improve performance.
Developers can also optimise deep learning algorithms through pruning. Pruning involves removing rarely used artificial neurons from the neural network. This can minimise the size of ML models and speed up the inference process. Pruning also doesn’t significantly impact accuracy. Pruning can even improve accuracy because it reduces noise within the training set. Many data scientists choose to iteratively prune neural networks to avoid damaging them.
Data curation
Companies need to curate the data that’s collected. This helps overcome variances, especially when it comes to Big Data. Digital signal processing can filter raw data from sensors to extract the most interesting information. Filtering is especially useful for IoT devices with a high noise-to-signal ratio. This means there’s irrelevant data that can cause network congestion and data storage problems without adding value.
Curating data can lead to better results with limited datasets. This reduces the processing requirements for the ML implementation. That means it’s possible to only use information-rich data as input for ML models. This ensures there are patterns to discover no matter the algorithm. Signal processing, therefore, is critical in embedded systems environments with rigid limitations.
Inference processing
Finally, companies should consider offloading data processing tasks. Cloud resources can handle tasks that aren’t time or privacy-sensitive. This can reduce the burden on local processors while ensuring value is extracted from the data. Cloud-based computing can also allow for a more in-depth analysis of the data. Resource-intensive algorithms still aren’t possible with on-device machine learning.
However, inference engines at the edge make sense in some situations. For example, keeping data with security and privacy concerns, or even merely competitive value, from reaching outside networks. For this, developers should choose lean inference engines. These eliminate unnecessary code and rarely used features. Lightweight inference engines can run on the constrained resources of microcontrollers.
Wrapping it up
Embedded ML can improve business operations, but the implementation needs to be purpose-built. Organisations should consider a software team that develops embedded systems. That way, the ML solution is designed to work within the constraints of embedded environments.
Bluefruit Software is an embedded software development company with over 20 years of low-level embedded systems and firmware expertise. Our development team has helped clients build custom embedded systems software for over 100 products. Many of these solutions included the implementation of machine learning models.
In one project, we integrated machine learning into an embedded device. The client specialises in business-critical communications across a wide range of industries. The embedded device provides real-time engine monitoring to help companies plan for ongoing maintenance or critical repairs. We built this device software to leverage on-device ML so that it could be deployed in extreme environments without reliable internet connections.
At Bluefruit, production quality is a primary focus. That’s why we ensure every project we deliver meets the needs of safety and security-critical environments without compromising on performance. With Lean-Agile principles, we can iteratively build solutions and adapt to evolving business requirements to achieve the best outcome possible.
Why is psychological safety critical to managing software risk?
Are you wondering what it really takes to prevent hazards and harms from embedded devices and systems? The tool many organisations are missing from their software development and product teams’ toolboxes:
Psychological safety.
You can download your copy of Why is psychological safety critical to managing software risk today. It doesn’t matter if you’re new to the concept or need a refresher; in our new ebook, you’ll learn about:
- What is psychological safety?
- The four stages vital to building psychological safety within teams.
- How psychological safety diminishes project risk.
- Project management practices that work well in organisations with psychological safety.
- How two businesses squandered psychological safety and paid the price for it.
Further reading
Did you know that we have a monthly newsletter?
If you’d like insights into software development, Lean-Agile practices, advances in technology and more to your inbox once a month—sign up today!
Find out more